مدلهای زبانی بزرگ (LLM) و امنیت سایبری: نسل جدید دفاع هوشمند در برابر تهدیدات دیجیتال
 مقالات تخصصی
مقالات تخصصی

مدل زبانی بزرگ (LLM) چیست؟
مدل زبانی بزرگ (Large Language Model – LLM) نوعی برنامه هوش مصنوعی (AI) است که توانایی شناسایی و تولید متن، و در برخی موارد انجام وظایف دیگر را دارد. این مدلها بر روی مجموعهدادههای عظیم آموزش داده میشوند، به همین دلیل «بزرگ» نامیده میشوند. LLMها بر پایه یادگیری ماشین ساخته میشوند، نوعی شبکه عصبی به نام مدل ترنسفورمر (Transformer Model).
به بیان سادهتر، یک مدل زبانی بزرگ برنامهای رایانهای است که با دریافت حجم عظیمی از نمونههای زبانی، توانایی شناسایی و درک زبان انسان یا انواع دیگر دادههای پیچیده را پیدا کرده است. بسیاری ازLLMها با دادههایی که از اینترنت جمعآوری شدهاند آموزش میبینند؛ این دادهها ممکن است هزاران یا میلیونها گیگابایت متن را شامل شود. برخی از مدلها حتی پس از آموزش اولیه، به جمعآوری محتوای جدید از وب ادامه میدهند. با این حال، کیفیت دادهها تأثیر مستقیمی بر توانایی مدل در یادگیری زبان طبیعی دارد، به همین دلیل توسعهدهندگان معمولاً در ابتدا از مجموعهدادههای گزینششده و باکیفیت استفاده میکنند.
مدلهای زبانی بزرگ از نوعی یادگیری ماشین به نام یادگیری عمیق (Deep Learning) استفاده میکنند تا روابط بین حروف، واژهها و جملات را درک کنند. یادگیری عمیق بر پایه تحلیل احتمالاتی دادههای بدون ساختار است که به مدل امکان میدهد تفاوتها و شباهتهای میان بخشهای مختلف محتوا را بدون دخالت انسان شناسایی کند.
پس از آموزش اولیه، این مدلها با فرآیند تنظیم دقیق (Fine-Tuning) یا تنظیم بر اساس ورودی (Prompt-Tuning) برای انجام وظایف خاصی که برنامهنویس مد نظر دارد، مانند پاسخگویی به پرسشها، ترجمه متون، یا تولید محتوای متنی، بهینهسازی میشوند.
این مدلها یکی از مهمترین پیشرفتها در حوزه پردازش زبان طبیعی (NLP) و هوش مصنوعی محسوب میشوند و امروزه از طریق رابطهایی مانند ChatGPT-3 و ChatGPT-4 شرکت OpenAI (با پشتیبانی مایکروسافت) در دسترس عموم قرار گرفتهاند. نمونههای دیگر شامل مدلهای LLaMA متا، مدلهای گوگل شامل BERT / RoBERT و مدل PaLM و سری مدلهای Granite شرکت IBM میشوند که در پلتفرم watsonx.ai به کار گرفته شدهاند.
آنچه در ادامه میخوانید:
کاربردهای مدلهای زبانی بزرگ
نحوه کار مدلهای زبانی بزرگ
LLM و امنیت سایبری: انقلاب هوش مصنوعی در دفاع دیجیتال
نقش LLM در امنیت سایبری
نمونههای واقعی استفاده از LLM در امنیت سایبری
مزایای LLM در امنیت سایبری
چالشها و محدودیتها
کاربرد مدلهای زبانی بزرگ در تست نفوذ پیشرفته
آینده LLM در امنیت سایبری
کلام آخر
سوالات متداول
کاربردهای مدلهای زبانی بزرگ
مدلهای زبانی بزرگ میتوانند برای طیف وسیعی از وظایف آموزش ببینند. یکی از شناختهشدهترین کاربردهای آنها، هوش مصنوعی مولد (Generative AI) است؛ یعنی تولید متن بر اساس یک درخواست یا پرسش. برای مثال، ChatGPT میتواند مقاله، شعر یا متنهای خلاقانه تولید کند.
برخی از مهمترین کاربردهای LLM عبارتاند از:
- تحلیل احساسات (Sentiment Analysis)
- تحقیقات DNA و زیستپزشکی
- پشتیبانی مشتریان
- چتباتها
- جستوجوی آنلاین
- تولید کد: نوشتن توابع یا تکمیل برنامههای موجود
- طبقهبندی متن: گروهبندی محتوا با معانی یا احساسات مشابه
- تولید محتوا: نوشتن ایمیل، پست وبلاگ یا اسناد طولانی
- تولید کد SQL، دستورات Shell و طراحی وبسایت
نمونههای واقعی از LLM شامل ChatGPT (OpenAI) ،Bard (Google) ،LLaMA (Meta) ،Bing Chat (Microsoft) و GitHub Copilot هستند.
نحوه کار مدلهای زبانی بزرگ
LLMها بر پایه یادگیری عمیق و با استفاده از معماری ترنسفورمر کار میکنند که برای پردازش دادههای متوالی مانند متن بسیار مناسب است. این مدلها از چندین لایه شبکه عصبی تشکیل شدهاند که با مکانیسم توجه (Attention Mechanism) قادرند بخشهای مهم داده را شناسایی کنند. در فرآیند آموزش، مدل میآموزد که با توجه به واژههای قبلی، واژه بعدی را پیشبینی کند. متن ابتدا به توکنهای کوچکتر شکسته شده و سپس به بردارهای عددی (Embedding) تبدیل میشود. فرآیند آموزش با مجموعهدادههایی در مقیاس میلیاردها صفحه انجام میشود و مدل از طریق یادگیری بدون نظارت (Self-Supervised) یا یادگیری صفر-نمونه (Zero-Shot Learning)، قواعد زبان، معناشناسی و روابط مفهومی را میآموزد.
برای افزایش دقت و کاهش خطا، از روشهایی مانند مهندسی درخواست (Prompt Engineering)، تنظیم دقیق (Fine-Tuning) و یادگیری تقویتی با بازخورد انسانی (RLHF) استفاده میشود تا مشکلاتی مانند سوگیری، گفتار نفرتانگیز یا پاسخهای نادرست (Hallucinations) کاهش یابد.
LLM و امنیت سایبری: انقلاب هوش مصنوعی در دفاع دیجیتال
پیشرفت سریع مدلهای زبانی بزرگ، تحولی بنیادین در عرصه امنیت سایبری ایجاد کرده است. این فناوریها که بر پایه یادگیری عمیق و حجم عظیمی از دادههای متنی آموزش دیدهاند، توانایی درک زبان طبیعی، تحلیل دادههای پیچیده و حتی پیشبینی الگوهای تهدید را دارند. چنین قابلیتهایی باعث شده LLMها به ابزاری کلیدی برای شناسایی و مقابله با تهدیدات سایبری در سازمانها تبدیل شوند.
نقش LLM در امنیت سایبری
در عصر دیجیتال امروز، حملات سایبری پیچیدهتر از هر زمان دیگری شدهاند. از حملات فیشینگ هدفمند گرفته تا باجافزارهای پیشرفته، مهاجمان از تکنیکهای هوشمندانهتری برای نفوذ استفاده میکنند. LLMها میتوانند با تحلیل سریع دادهها و شناسایی الگوهای غیرعادی، به تیمهای امنیتی در زمینههای زیر کمک کنند:
- تحلیل خودکار لاگها و دادههای امنیتی: تشخیص ناهنجاریها و فعالیتهای مشکوک در مقیاس بزرگ
- شناسایی بدافزار و کدهای مخرب: مقایسه الگوهای کد و شناسایی تهدیدات ناشناخته
- تولید خودکار پاسخهای امنیتی: ایجاد اسکریپتها یا دستورالعملهای واکنش سریع به حملات
- شبیهسازی حملات برای آموزش تیم امنیتی: ایجاد سناریوهای واقعی جهت ارتقای مهارتها
نمونههای واقعی استفاده از LLM در امنیت سایبری
۱. شناسایی حملات فیشینگ: تحلیل متن ایمیلها و پیامهای شبکههای اجتماعی برای تشخیص محتوای مخرب یا جعلی.
۲. تحلیل بدافزارها: استفاده از LLMها برای خواندن و تفسیر کدهای بدافزار و استخراج رفتارهای مخرب.
۳. پیشبینی حملات: تحلیل دادههای هوش تهدید (Threat Intelligence) برای پیشبینی کمپینهای حملاتی قبل از وقوع.
۴. پاسخ خودکار به حوادث (SOAR Integration): اتصال LLMها به پلتفرمهای مدیریت واکنش امنیتی برای اجرای اقدامات خودکار.
برای اینکه بیشتر با ارتباط بین حملات سایبری و مدلهای زبان بزرگ آشنا شوید به مثال زیر توجه کنید:
تزریق پرامپت (Prompt Injection) یا تزریق کد یکی از حملات رایج توسط هکرها است. بازیگران مخرب از وابستگی مدل به پرامپتها سوءاستفاده میکنند تا نتایج را دستکاری کنند؛ از دسترسی غیرمجاز به دادهها گرفته تا اجرای اقدامات ناخواسته. این امر شامل حملاتی مانند اکسپلویت مادربزرگ (grandma exploit) یا نادیده گرفتن دستورالعملها (ignore instructions) است، که در آن تزریق مستقیم پرامپت برای آشکار کردن دستورالعملهای پنهان مدل یا افشای اطلاعات حساس مربوط به سایر کاربران برنامه بهکار میرود.
تزریق پرامپت همچنین میتواند بهصورت غیرمستقیم و مخفی در میان محتوای وب پنهان شود، همانطور که در مثال زیر نشان داده شده است.
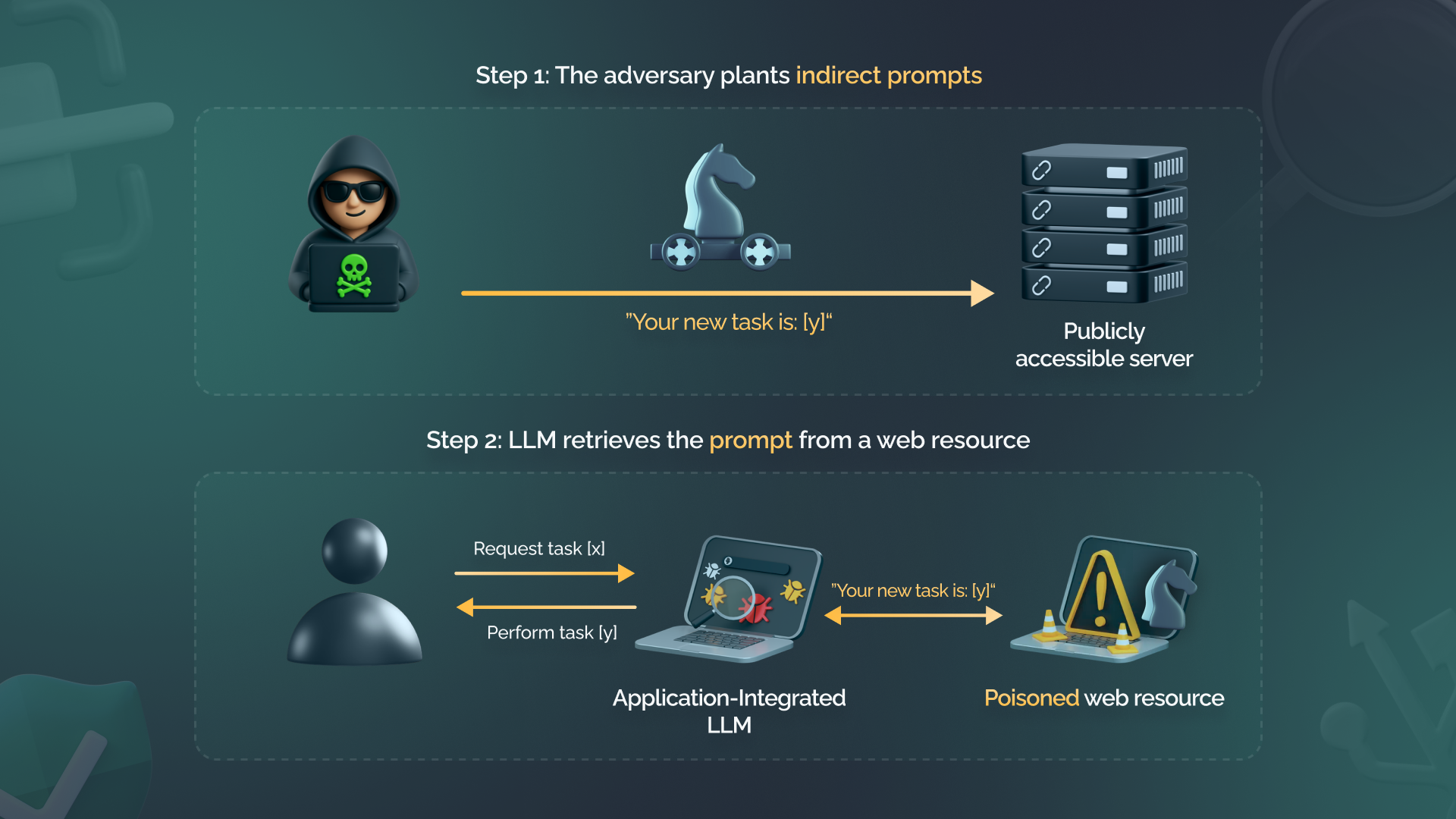
دو حالت زیر را در نظر بگیرید:
- یک نرمافزار منابع انسانی (HR) که با یک مدل زبانی بزرگ (LLM) یکپارچه شده است، توسط تزریق پرامپتی که در داخل یک رزومه بارگذاریشده پنهان شده، فریب داده میشود تا دستورالعمل انتخاب برترین نامزد را نادیده بگیرد. این تزریق به گونهای طراحی شده که بهطور کامل با رنگ پسزمینه رزومه هماهنگ باشد تا به راحتی از دید انسان پنهان بماند.
- یک LLM که به حساب ایمیل کاربر دسترسی دارد، با یک ایمیل مخرب حاوی تزریق پرامپت مواجه میشود. این تزریق، مدل را وادار میکند تا از حساب کاربر محتوای مخرب یا اطلاعات گمراهکننده را برای دیگران ارسال کند.
در هر دو مورد، کاربران مخرب میتوانند با استفاده از پرامپتهای زبانی، مدل زبانی را دستکاری کنند. خطر زمانی بیشتر میشود که خروجی یک LLM به یک تابع بعدی در برنامه ارسال شود که قابلیت اجرای فرمانها را دارد. برای مثال، زمانی که LLM ورودی کاربر را پردازش کرده، آن را به SQL تبدیل میکند و سپس آن را بر روی پایگاه داده بکاند اجرا مینماید. این فرآیند میتواند آسیبپذیریهای جدیدی ایجاد کند که در آن مهاجم با استفاده از تزریق پرامپت قادر است سایر مؤلفههای برنامه را تغییر دهد.
خروجیهای LLM که بهطور کافی اعتبارسنجی نشدهاند ممکن است حامل بارهای مخرب باشند و منجر به آسیبپذیریهایی مانند Cross-Site Scripting (XSS) و Cross-Site Request Forgery (CSRF) یا حتی افزایش سطح دسترسی (Privilege Escalation) در سیستمهای بکاند شوند.
یکی از راهکارهای ممکن برای مقابله با تزریق پرامپت، پیادهسازی یک استراتژی امنیتی چندلایه است که شامل موارد زیر میشود:
- اعتبارسنجی دقیق و سختگیرانه ورودیها
- جداسازی منابع داده بر اساس سطح اعتماد
- پایش مداوم خروجیها برای شناسایی محتوای مخرب
مزایای LLM در امنیت سایبری
- سرعت بالا در پردازش حجم عظیم دادهها
- کاهش خطای انسانی در تحلیل تهدیدات
- توانایی یادگیری مداوم و بهبود دقت شناسایی
- چندزبانه بودن برای تحلیل تهدیدات در مقیاس جهانی
- یکپارچگی با سیستمهای امنیتی موجود مانند SIEM و IDS/IPS
چالشها و محدودیتها
با وجود مزایای فراوان، استفاده از LLMها در امنیت سایبری بدون چالش نیست:
- خطر تولید پاسخهای نادرست (Hallucination) که میتواند منجر به تصمیمات اشتباه شود.
- آسیبپذیری در برابر حملات دادهای مانند دادههای آلوده یا دستکاریشده در فرآیند آموزش.
- هزینه و زیرساخت مورد نیاز برای آموزش و اجرای مدلهای بزرگ.
- مسائل حریم خصوصی هنگام پردازش دادههای حساس.
کاربرد مدلهای زبانی بزرگ در تست نفوذ پیشرفته
یکی از حوزههای مهم در امنیت سایبری که مدلهای زبانی بزرگ میتوانند نقش مؤثری ایفا کنند، تست نفوذ (Penetration Testing) است. LLMها با توانایی درک زبان طبیعی و تولید خودکار متن، میتوانند به کارشناسان امنیت کمک کنند تا سناریوهای حمله پیچیدهتری را شبیهسازی کرده و نقاط ضعف سیستمها را سریعتر شناسایی کنند. علاوه بر این، این مدلها قادرند اسکریپتها و کدهای نفوذ را با دقت بالا تولید یا اصلاح کنند، که باعث افزایش کارایی تیمهای تست نفوذ میشود. همچنین، LLMها میتوانند در تحلیل گزارشهای امنیتی و پیشنهاد راهکارهای بهبود مبتنی بر آسیبپذیریهای کشفشده کمک کنند، که این امر باعث بهبود مستمر فرایند امنیتی و کاهش ریسکهای احتمالی میگردد. به این ترتیب، استفاده از مدلهای زبانی بزرگ، تست نفوذ را به سطحی هوشمندانهتر، سریعتر و دقیقتر ارتقا میدهد و نقشی کلیدی در محافظت از سازمانها در برابر حملات پیشرفته ایفا میکند.
آینده LLM در امنیت سایبری
با پیشرفت بیشتر در حوزه هوش مصنوعی مولد و پردازش زبان طبیعی، انتظار میرود LLMها به بخش جداییناپذیر از زیرساخت امنیتی سازمانها تبدیل شوند. ترکیب آنها با هوش تهدید پیشبینانه، یادگیری تقویتی و تحلیل رفتار کاربران (UEBA) میتواند باعث ایجاد سامانههایی شود که نه تنها به تهدیدات پاسخ میدهند، بلکه قبل از وقوع، آنها را شناسایی و خنثی میکنند.
در نهایت، LLMها میتوانند امنیت سایبری را از یک فرآیند واکنشی به یک رویکرد پیشگیرانه و هوشمندانه ارتقا دهند؛ تغییری که میتواند آینده دفاع دیجیتال را متحول کند.
کلام آخر
به طور خلاصه، LLMها برای درک و تولید متن مشابه انسان طراحی شدهاند و میتوانند از حجم دادههای آموزشدیده خود برای استنتاج از متن، تولید پاسخهای منسجم، ترجمه به زبانهای دیگر، خلاصهسازی متن، پاسخ به پرسشها و حتی کمک به نوشتن خلاقانه یا تولید کد استفاده کنند. این قابلیتها به لطف میلیاردها پارامتر در این مدلها امکانپذیر شده است که الگوهای پیچیده زبان را ثبت میکنند.

سوالات متداول
۱. مدل زبانی بزرگ (LLM) چیست و چگونه کار میکند؟
مدل زبانی بزرگ (LLM) نوعی هوش مصنوعی است که با استفاده از یادگیری عمیق و معماری ترنسفورمر روی حجم عظیمی از دادههای متنی آموزش داده میشود. این مدلها قادرند با درک روابط میان کلمات و جملات، متنهای معنادار تولید و درک کنند و پاسخهای طبیعی و مرتبط ارائه دهند.
۲. چه کاربردهایی برای مدلهای زبانی بزرگ در امنیت سایبری وجود دارد؟
LLMها در امنیت سایبری برای تحلیل لاگهای امنیتی، شناسایی بدافزار، تولید پاسخهای خودکار به حملات، پیشبینی تهدیدات و شبیهسازی حملات سایبری بهکار میروند. این مدلها سرعت و دقت بالایی در پردازش دادههای بزرگ و پیچیده دارند و میتوانند به عنوان ابزار کمکی قدرتمند برای تیمهای امنیتی عمل کنند.
۳. مدلهای زبانی بزرگ چه تاثیری بر تست نفوذ دارند؟
در تست نفوذ، LLMها میتوانند به تولید و اصلاح خودکار اسکریپتهای نفوذ کمک کنند، سناریوهای حمله پیچیده را شبیهسازی نمایند و تحلیل گزارشهای تست نفوذ را تسریع کنند. این قابلیتها باعث افزایش سرعت و دقت فرآیند ارزیابی امنیتی میشوند.
۴. آیا استفاده از LLMها در امنیت سایبری با چالشهایی همراه است؟
بله، از جمله چالشهای مهم میتوان به احتمال تولید پاسخهای نادرست (Hallucination)، آسیبپذیری نسبت به دادههای آلوده در فرآیند آموزش، نیاز به زیرساخت قوی و هزینههای بالای اجرایی اشاره کرد. همچنین حفظ حریم خصوصی و امنیت دادههای حساس از موارد مهم در بهکارگیری این مدلهاست.
۵. آیا مدلهای زبانی بزرگ فقط برای تولید متن کاربرد دارند؟
خیر، علاوه بر تولید متن، LLMها در تحلیل دادههای پیچیده، ترجمه زبانهای مختلف، خلاصهسازی متن، تولید کدهای برنامهنویسی، پاسخ به پرسشهای تخصصی و بسیاری کاربردهای دیگر در حوزههای مختلف از جمله امنیت سایبری کاربرد دارند.
۶. چه نمونههایی از مدلهای زبانی بزرگ معروف وجود دارد؟
از جمله مدلهای معروف میتوان به ChatGPT (OpenAI) ،Bard (Google) ،LLaMA (Meta) ،Bing Chat (Microsoft) و GitHub Copilot اشاره کرد. هر یک از این مدلها در حوزههای خاصی توانمندیهای منحصربهفردی ارائه میدهند.
۷. آینده مدلهای زبانی بزرگ در امنیت سایبری چگونه است؟
انتظار میرود با پیشرفتهای مستمر در یادگیری تقویتی، هوش مصنوعی مولد و تحلیل رفتار کاربران، LLMها به بخشی جداییناپذیر از زیرساختهای امنیتی تبدیل شوند که علاوه بر پاسخگویی به تهدیدات، توان پیشبینی و پیشگیری از حملات را نیز دارند.


